任务执行
Crawlab的任务执行依赖于shell。执行一个爬虫任务相当于在shell中执行相应的命令,因此在执行爬虫任务之前,要求使用者将执行命令存入数据库。执行命令存在spiders表中的cmd字段。
任务执行的架构示意图如下。
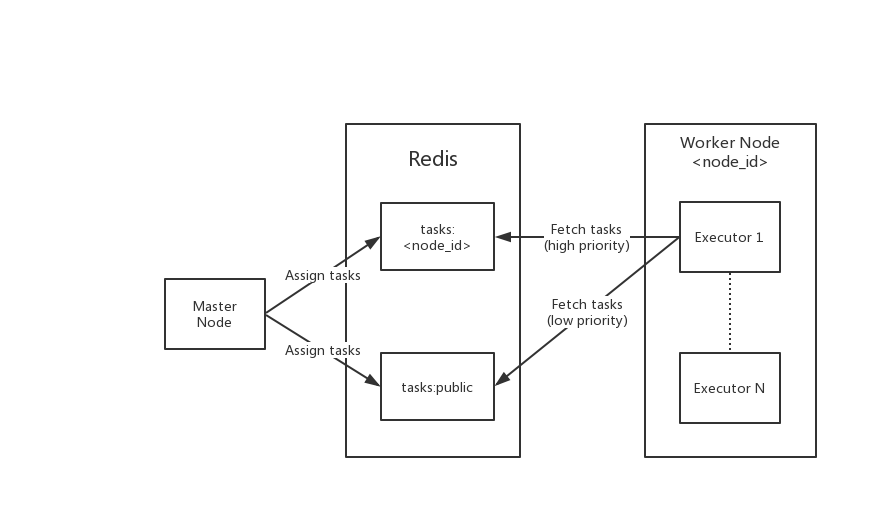
当爬虫任务被派发时,主节点会在Redis中的tasks:<node_id>(指定工作节点)和tasks:public(任意工作节点)派发任务,也就是RPUSH命令。
工作节点在启动时会起N个执行器(通过环境变量CRAWLAB_TASK_WORKERS配置,默认为4),每个执行器会轮训Redis的消息队列,优先获取指定节点消息队列tasks:<node_id>,如果指定队列中没有任务,才会获取任意节点消息队列中的任务tasks:public。
执行过程的具体情况就不细述了,详情请见源码。